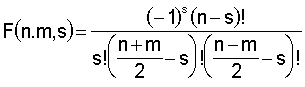
D„nut Moraru
Atunci c‚nd dorim s„ proiect„m o aplicatie mare consumatoare de resurse de calcul (ori s„ "paraleliz„m" o aplicatie existent„) si nu avem o masin„ paralel„ puternic„, e bine s„ privim Ón jur. S-ar putea s„ descoperim c„ acele calculatoare din laborator, folosite p‚n„ acum independent, ne pot oferi Ómpreun„ puterea de calcul de care avem nevoie. Tot ce avem de f„cut este s„ adapt„m algoritmii si s„ g„sim implementarea potrivit„ pentru hardware-ul ce-l avem la Óndem‚n„.
Ideal pentru a dezvolta si rula o aplicatie distribuit„ este de a avea la Óndem‚n„ o retea omogen„ de calcul, deci cuprinz‚nd noduri de procesare puternice, identice, Ómpreun„ cu un mediu de dezvoltare dedicat arhitecturii respective (adic„ trusa de "scule" software pentru scrierea, testarea, depanarea si executia programelor rezultate, Ómpreun„ cu biblioteci de rutine, manuale, exemple). Acestea Óns„ cost„ mult, iar dac„ avem bani putini si pretentii mai mici, cu un bun raport performant„/pret sunt accesibile arhitecturile cu transputere.
Retelele eterogene de calcul sunt Óns„ mult mai r„sp‚ndite. Unul din motive ar fi si faptul c„ reunesc masini din generatii diferite, cu arhitecturi diferite, cu sisteme de operare diferite, achizitionate de-a lungul timpului de la produc„tori diferiti, prin eforturi investitionale esalonate. Un alt motiv ar fi si c„ fiecare component„ din retea a fost achizitionat„ cu un scop anume: o masin„ spre a fi utilizat„ ca file server, alta pentru capabilit„tile grafice deosebite, o alta pentru interfetele incluse care ne convin de minune pentru achizitia noastr„ de date, etc. De foarte multe ori, notiunea de "retea" vine numai de la faptul c„ aceste masini sunt legate pe acelasi cablu, schimb‚nd din c‚nd Ón c‚nd c‚te un fisier Óntre ele, mai comod dec‚t mut‚nd discheta din unitatea unuia Ón a celuilalt. Poate c„ aceste calculatoare nu au fost puse niciodat„ s„ conlucreze Ón executia unei aplicatii.
Cum s-ar putea pune Ómpreun„ la lucru aceste calculatoare, at‚t de diferite ca arhitecturi, sisteme de operare, av‚nd procesoare diferite ca performante? Platforma comun„ este posibilitatea de a comunica. Iar la acest capitol, din fericire, exist„ numeroase standardiz„ri, at‚t la nivel fizic - mediul de comunicatie, semnale electrice, timpi, c‚t si la nivel logic - de atribuire a anumitor semnificatii si de organizare a datelor interschimbate.
La sistemele omogene, comunicatia Óntre noduri se bazeaz„ de obicei pe protocoale "interne" firmei care a proiectat si procesoarele (neaplicabile si altor arhitecturi), subsistemul ce se ocup„ de comunicatii fiind inclus adeseori pe cipul procesor. Este cazul transputerelor, care comunic„ prin intermediul leg„turilor seriale de mare vitez„ (5-20 MB/s). Œn schimb, Ón cazul sistemelor eterogene, tipul de retea folosit„ este "de larg„ r„sp‚ndire", pentru care majoritatea firmelor produc cartele de interfatare cu masina proprie. Ca exemple, retelele de tip Ethernet sau Token Ring asigur„ debite de ordinul a 10 MB/s. Debitul maxim de informatie permis de retea reprezint„ un factor important mai ales Ón sisteme puternic comunicante. Œn analiza oric„rui algoritm, el trebuie corelat cu viteza procesoarelor de a executa instructiuni si de a face calcule. Necorelarea duce la sc„derea global„ a eficientei, datorat„ timpilor morti suplimentari din cauza aglomer„rii retelei.
Exist„ actualmente o multime de protocoale de nivel Ónalt pe baza c„rora se realizeaz„ comunicatiile. Totodat„, sunt disponibile biblioteci de rutine apelabile din limbaje de programare de nivel Ónalt, care ofer„ servicii de transfer de date Ón retea, bazate pe protocoalele respective. Utilizatorul va folosi (prin intermediul bibliotecilor) acele protocoale implementate pe toate sistemele pe care Ósi va rula aplicatia, care i se potrivesc aplicatiei sale si de ce nu - pe care le cunoaste mai bine.
Retelele locale sunt cunoscute sub denumirea de "retele cu comutare de pachete". Aceasta Ónseamn„ c„ datele transferate prin retea sunt Ómp„rtite Ón pachete cu m„rimi maxime tipic Ón gama 512 - 4096 octeti (MTU - Maximal Transfer Unit). Fiecare pachet este transferat independent de celelalte si poate urma o cale diferit„ de la emit„tor la receptor.
Caracteristicile pe care le vom urm„ri la serviciile de comunicatie Ón retea sunt:
Un serviciu orientat conexiune cere ca cele dou„ aplicatii s„ stabileasc„ Óntre ele o conexiune logic„ Ónainte de a avea loc comunicatia si este folosit„ c‚nd mai mult de un mesaj urmeaz„ s„ fie schimbat Óntre cele dou„ entit„ti. Aplicatiilor care comunic„ li se stabileste un circuit virtual, chiar dac„ fluxul de date are loc utiliz‚nd o retea cu comutare de pachete. Se foloseste atunci c‚nd aplicatiile anticipeaz„ un schimb Óndelungat de date.
Un serviciu f„r„ conexiune (orientat datagram„) const„ Ón transmiterea mesajelor independent, fiecare trebuind s„ contin„ toate informatiile cerute pentru livrarea sa. Se utilizeaz„ acolo unde aplicatiile vor schimba date f„r„ o planificare prealabil„.
- Sum„ de control inclus„ Ón fiecare pachet, spre a fi verificat„ de receptor.
- Achitare pozitiv„: notificarea emit„torului c„ pachetul a ajuns corect sau eronat la destinatie. Œn caz de eroare, emit„torul retransmite pachetul Ón cauz„. Confirmarea se poate face (la serviciile orientate conexiune) pe grup de pachete - mai eficient„ dec‚t confirmarea pentru fiecare pachet.
- Retransmitere dup„ timeout: dac„ dup„ expirarea intervalului de timeout, nu s-a primit confirmarea de receptie (pachet pierdut), emit„torul retransmite pachetul Ón cauz„.
Un aspect deloc de neglijat atunci c‚nd avem procesoare din familii diferite este reprezentarea datelor multioctet. Unele procesoare aranjeaz„ Ón memorie octetul cel mai semnificativ la adrese mici (formatul big-endian), iar altele la adrese mari (formatul little-endian). Din prima categorie fac parte procesoare ca Motorola 68000, RS6000, iar din a doua categorie Intel 80x86, VAX. Bibliotecile care ofer„ servicii de comunicare asigur„ si rutine de conversie (Ón ambele sensuri) Óntre formatul standard definit de protocol si formatul procesorului local. Astfel, spre exemplu, protocoalele TCP/IP cer reprezentare tip big endian. Diferente exist„ si Ón reprezentarea Óntregilor. Unele implement„ri de C "stiu" s„ reprezinte un Óntreg pe doi octeti, altele pe patru. Nepotriviri pot ap„rea si la reprezentarea numerelor flotante, desi exist„ si aici standarde (exemplu: IEEE 754).
Ca solutie la problemele prezentate anterior, exist„ biblioteci si servicii run-time care Ól scutesc pe programator de grija conversiei corecte a datelor. Cu RPC (Remote Procedure Call) programatorul are senzatia c„ un serviciu cerut unui server la distant„ se execut„ ca o procedur„ local„. Clientul va trebui Óns„ s„ astepte inactiv returnarea din procedur„.
Mai mult, exist„ medii de programare si executie a aplicatiilor paralele, care permit unei retele eterogene de calculatoare s„ fie vazut„ ca o singur„ masin„ paralel„ virtual„. Ca exemple: PVM (prezentat Ón acest num„r) si P4. Acestea sunt deocamdat„ disponibile doar pe Unix.
Exemplul pe care Ól prezint (calculul invariantilor Zernike pentru un set de imagini) face parte dintr-o aplicatie complex„ de recunoastere de obiecte din imagini reale 2D, preluate cu videocamera sau scannerul (aduse la format bitmap), bazat„ pe retele neuronale artificiale. "Obiectele" pe care le-am Óncercat au fost piese electronice, litere de tipar etc.
Œn urma detectiei unui num„r de obiecte Óntr-o imagine, se pune problema de a g„si pentru fiecare obiect o reprezentare numeric„ de dimensiune redus„ si constant„ indiferent de dimensiunile, pozitia, unghiul de rotatie si factorul de scalare al obiectului Ón imagine, potrivit„ aplic„rii la intrarea unei retele neuronale. Una dintre solutiile la aceast„ problem„ o constituie calcularea momentelor Zernike ale imaginii obiectului - un set de numere complexe cu proprietatea c„ modulele acestora au aceeasi valoare, indiferent de orientarea (unghiul de rotatie) obiectului Ón imagine. Invarianta la pozitia Ón imagine se asigur„ prin algoritmul de detectie si Óncadrare a fiec„rui obiect Ón cercul de raz„ minim„ si Ón dreptunghiul minim.
Practic, aplicatia a fost proiectat„ initial Ón C++ pentru Windows 3.1, rul‚nd independent, iar ulterior a fost reproiectat„ si "distribuit„" pe mai multe calculatoare. Modelul folosit pentru varianta distribuit„ este "ferma de procesoare".
O ferm„ de procesoare se compune dintr-un singur client (numit fermier sau st„p‚n) si mai multe servere (lucr„tori sau sclavi). Aceasta este oarecum invers situatiilor obisnuite, Ón care un singur server deserveste mai multi clienti. Fermierul (farmer) divide munca Ón mai multe sarcini si pentru Ónceput, trimite fiec„rui lucr„tor (worker) c‚te una. De Óndat„ ce un lucr„tor a terminat sarcina curent„ si Óntoarce rezultatul muncii sale, va primi imediat o nou„ sarcin„. Procesul se Óncheie atunci c‚nd toate sarcinile s-au Óncheiat si au fost primite toate rezultatele. Œn cazul de fat„, "fermierul" ruleaz„ pe un PC cu Windows 3.1 sau 3.11, iar "lucr„torii" pe PC-uri cu Windows si masini cu UNIX-uri ca Solaris, AIX, Linux.
Comunicatiile Óntre masini se bazeaz„ pe TCP, care este orientat conexiune. A fost ales pentru compatibilitatea cu sistemele existente, dar si pentru facilit„tile de control al erorilor, foatre bine put‚ndu-se folosi UDP - serviciu orientat datagram„, care nu ofer„ Óns„ sigurant„. Pentru serviciile de retea, aplicatiile Windows 3.1 folosesc biblioteca winsock.dll (Windows 3.11 si Windows 95 au capabilit„tile de TCP/IP Óncorporate), iar aplicatiile UNIX apelurile sistem pentru lucru cu socluri (sockets) - vezi bibliografia.
Pornind de la versiunea secvential„ a algoritmului pentru calcularea momentelor Zernike, p„rtile care pot fi executate Ón paralel trebuiesc identificate. O evaluare a timpului total cerut pentru calcule, comparativ cu timpul pentru comunicatie, poate fi decisiv„ pentru a alege o solutie de paralelizare sau alta.
Œn cele ce urmeaz„, vor fi utilizate urm„toarele conventii:
ORDMAX = ordinul maxim pentru momentele Zernike calculate.
MOMMAX = num„rul de momente Zernike corespunz„tor num„rului dat ORDMAX.
Anm[MOMMAX] = vector complex continÓnd momentele Zernike calculate.
P(x,y) = valoarea pentru pixel (apartinÓnd obiectului) Ón coordonate (x,y) cu originea Ón centrul de greutate al obiectului.
O posibil„ implementare a algoritmului este "Listing 1 "
Dup„ cum se observ„, fiecare moment Zernike Anm[i] este calculat independent, deci este posibil s„ distribuim executia acestor bucle pentru diferite valori ale perechilor (n, m) (liniile 4 - 8) pe mai multe procesoare lucrÓnd separat. Acesta ar putea fi un avantaj, dac„ reteaua are posibilitatea de "broadcasting", astfel ÓncÓt valorile pixelilor apartinÓnd unui obiect vor fi tramsmiti de c„tre fermier o dat„ pentru toti lucr„torii simultan. Dup„ aceea, fiecare lucr„tor va executa calculele pentru un num„r de momente Zernike si va raporta rezultatele fermierului. Putem Ómp„rti egal volumul total de calcule tuturor lucr„torilor, astfel ÓncÓt fiecare lucr„tor va executa aproximativ MOMMAX / N bucle. Este cerut dialogul initial dintre fermier si lucr„tori, astfel ÓncÓt fiecare lucr„tor s„ obtin„ gama pentru valorile n si m pentru care va face calculele. Dezavantajul acestei tehnici de Ómp„rtire a buclelor (loop-splitting) este c„ Ón mediu eterogen, procesoarele lucreaz„ la viteze diferite, iar cele mai rapide vor fi neocupate pÓn„ ce cele mai lente Ósi vor termina lucrul. Œn plus, buclele nu sunt egale ca volum de calcule, depinzÓnd de valorile pentru n si m. Pentru echilibrarea Ónc„rc„rii, fermierul ar trebui s„ cunoasc„ "puterea" fiec„rui lucr„tor si s„ le trimit„ acestora corespunz„tor dimensiuni neegale ale gamelor pentru n si m.
Pe de alt„ parte, dac„ reteaua nu permite sau dac„ calculatoarele nu apartin aceleiasi retele locale, (desi exist„ protocoale care pot asigura "broadcasting" c„tre calculatoare apatinÓnd mai multor retele locale), aceast„ metod„ trebuie evitat„, deoarece aceleasi date trebuie transmise fiec„rui lucr„tor, care are nevoie de toti pixelii unui obiect.
S„ consider„m o alt„ implementare (vezi "Listing 2 ").
De data aceasta, pentru fiecare pixel, se vor calcula contributiile la toate momentele Zernike, unul cÓte unul. Fermierul trimite un Óntreg obiect unui singur lucr„tor si obtine momentele calculate. Pentru aceasta, se trimite mai Ónt‚i un header de dimensiune constant„, Ón care se specific„ caracteristicile obiectului (dimensiuni etc.), apoi se trimit efectiv pixelii obiectului - mai exact interiorul dreptunghiului de Óncadrare. Dou„ posibilit„ti au fost testate:
(a) Pixelii sunt copiati linie cu linie Óntr-un buffer, apoi trimisi printr-un singur apel socket write. Dac„ pachetul de date este prea lung, el va fi oricum Ómp„rtit Ón buc„ti, nedep„sindu-se MTU.
(b) Fiecare linie se transmite printr-un apel separat socket write.
Pentru cresterea vitezei de calcul, se poate recurge la mici artificii. Termenii de forma
se pot pre-calcula. Pentru MOMMAX =12, este necesar un vector de 140 de elemente. Mai mult, la ultima implementare (adoptat„ pentru aplicatie), pentru fiecare pixel, puterile lui r pot fi precalculate una c‚te una, Ónlocuind exponentierea cu Ónmultire si memor‚nd Óntr-un vector cu MOMMAX+1 valori. Aceste dou„ artificii m„resc viteza de trei ori !
Experimentele s-au f„cut cu ferma de procesoare const‚nd dintr-un farmer si un num„r variabil de workers (unul p‚n„ la patru) de tipuri diferite, conectate prin retea Ethernet. Spre comparatie, se dau rezultatele (Ón prima coloan„) pentru varianta de aplicatie mono-procesor (vezi tabelul).
F - farmer : PC486 DX2 cu Windows for Workgroups, 8MB RAM
r - worker: IBM RS 6000 cu AIX 3.2, 32MB RAM
s, g, a - workers: PC486 DX2 cu Linux., 16 MB RAM
Aceste masini nu au fost dedicate pentru aceast„ aplicatie. Timpul lor este partajat cu alte procese: a este gateway si server de domeniu, g este server de ftp si WWW, s este server de post„ si r este server pentru lucrul studentilor.
Este important de notat c„ fiecare obiect are dou„ dimensiuni importante:
Din acest motiv, pentru a efectua m„sur„torile de timp, au fost folosite seturi de imagini, fiecare contin‚nd 100 de obiecte identice (de fapt, dreptunghiuri mai "pline" sau mai "goale", generate cu Paintbrush):
- trei seturi de obiecte cu aria de 25 pixeli, dar cu dreptunghiuri de Óncadrare diferite: 5*5, 10*10 si 20*20 pixeli.
- trei seturi de obiecte cu aria de 400 pixeli, cu dreptunghiurile de Óncadrare de 20*20, 40*40 si 80*80 pixeli.
- un set de obiecte cu dreptunghiul de Óncadrare de 80*80, dar cu aria de 2800 pixeli.
Astfel, mentin‚nd aria constant„ si modific‚nd dreptunghiul de Óncadrare, variaz„ timpul pentru comunicatii. Mentin‚nd dreptunghiul de Óncadrare constant si variind aria obiectului, se modific„ proportional timpul afectat calculelor.
Se observ„ din tabel, asa cum ne asteptam, c„ metoda (a) este mai bun„ dec‚t (b) Ón toate situatiile. Pentru pachete mici, diferenta nu este at‚t de mare la PC-uri, dar este imens„ la RS6000. Pe m„sur„ ce dimensiunile obiectelor (deci si a pachetelor de date) cresc, diferentele dintre (a) si (b) scad. Œn schimb, RS6000 este net superior la viteza calculelor. Mai ciudat este c„ atunci c‚nd fermierul Ósi ruleaz„ aplicatia mono-procesor (deci Ón absenta oric„rei comunicatii), lucrurile merg mai prost dec‚t Ón versiunea cu un worker. Aceasta mi-o explic personal prin diferenta de RAM, managementul memoriei si a mesajelor Ón Windows si faptul c„ Linux foloseste puterea pe 32 de biti (iar Windows 3.11 pe 16 biti) a procesorului 486. Œn concluzie, se poate afirma c„ schimbul de date prin LAN este eficient dac„ pachetele sunt apropiate ca dimensiune de maximul admis (MTU). Linux manipuleaz„ mai bine pachetele de orice lungimi, dar RS6000 este mai rapid la calcule.